Virtual Desktop Infrastructure (VDI)
For years, IT pros have been trying their best to improve what has become a chaotic desktop management environment and to reduce costs for providing desktop computers. One of the original use cases around hyperconverged infrastructure was virtual desktop infrastructure (VDI).
VDI is an interesting solution. Like many trends in IT, VDI has gone through Gartner’s “hype cycle” (Figure 1). It went through both a period of sky-high expectations and also hit rock bottom as people became increasingly disillusioned with the technology. Today, however, it’s reaching the top end of the Slope of Enlightenment and entering the Plateau of Productivity.
Figure 1: Gartner’s hype cycle (courtesy of Wikipedia)
So how did we get to where we are?
VDI Through the Years
Long before x86-based virtualization became the norm, IT departments searched for ways to simplify and streamline desktop computing. Microsoft and Citrix led the way in this space and, for a time, their products were ubiquitous. People deployed thin clients based on specialized editions of Windows Server and had an adequate experience. Unfortunately, their experience was one that was mostly useful where terminals, not full desktop capabilities, were needed.
Then came along server virtualization. Server virtualization resulted in the ability to transform the business and IT — lowering costs while increasing productivity and efficiency along the way. With server virtualization, data center administrators could almost completely replicate their physical servers inside software with little to no loss of functionality.
At some point, someone somewhere had the bright idea to attempt to apply the same thinking to desktops in order to close the user-experience gap and make terminal-based desktops more like their PC brethren. Things didn’t work out quite so well. IT pros quickly discovered that their path to VDI success would be littered with very different challenges than those faced on the road to server virtualization.
Types of Virtual Desktops
There are two different kind of virtual desktops that you can use in a VDI environment: Persistent and Non-Persistent.
Persistent Desktops
Persistent desktops are the type that closely resemble desktop computers in the physical world. There is a 1:1 relationship between a virtual desktop and a user. In other words, a user has his or her own virtual desktop that no one else uses. This model is the most seamless from a user perspective since users have become used to having their own space. Persistent desktops require you to have sufficient storage for desktop customizations.
Non-Persistent Desktops
Think of a college computer lab: rows of computers available for any student, and students can go to different computers every day. The students really don’t care which computer they use each day as long as one is available and they don’t need to maintain user-specific settings. This is known as a non-persistent desktop. User settings are not maintained between sessions. Each time a user logs in, it’s as if he or she has logged in for the first time.
VDI Workload Differentiators
Although servers and desktops are both computers, how they’re used is very different. These differences have driven many of the challenges that doomed early VDI projects. Just because virtual desktops look like virtual servers, it doesn’t mean they act like them. Whereas server-based workloads will have their own performance peaks and valleys, they’re nothing compared to what happens in the world of the virtual desktop.
Linear Usage Patterns
In VDI environments, usage patterns directly follow user actions. When users log in or boot their virtual desktops in the morning, each virtual desktop undergoes significant storage I/O operations. Contrast this to a traditional PC, where you’ve probably seen it take minutes for computers to fully boot and login. This is because a lot of information has to be read from disk and placed into memory on a traditional PC. There are also write operations taking place, such as when Windows logs any exceptions that may take place at boot time.
Now, multiply all of this I/O by the number of users logging into their virtual desktops at the same time. In the world of the traditional desktop, each user has his or her own storage device (the local hard drive) to handle these I/O operations. In a VDI environment, the virtual desktops all share common storage systems, often a SAN or NAS device shared among the various hosts that house the virtual desktops. The amount of I/O that starts to hit storage can be in the hundreds, thousands, or even tens of thousands of IOPS.
The Failure and Resurgence of Storage
This was the problem in the early days of VDI. Then-current disk-based storage systems simply could not keep up with demands and quickly succumbed under the IOPS-based assault that came their way. This led directly to the hype cycle’s Trough of Disillusionment as people quickly discovered that there would be no return on their VDI investment because they had to buy shelves and shelves of disks to keep up with I/O demands. In technical terms, getting appropriate performance characteristics wasn’t cheap at all.
Shortly thereafter, flash storage started on its road into the enterprise. With the ability to eat IOPS faster than anything previously on the market, flash became a go-to technology for virtual desktops. It was used in many different ways, but flash carried its own baggage on the VDI journey. First, some of the flash-based solutions added complexity to storage, and second, all flash systems tended to be expensive.
Second-Class Citizenship for Data Protection
Protecting VDI environments was also a challenge. The nature of VDI didn’t always mean that it would enjoy the same kinds of data protection services as server workloads, even though desktop computing really is a critical service. Between WAN bandwidth and backup storage needs, fully protecting the desktop environment wasn’t always feasible.
It’s All About That Scale
Scaling VDI was, again, a far different chore than scaling server-centric workloads. Whereas server workloads were scaled based on individual resource need, VDI-based workloads scaled far more linearly, requiring RAM, compute, and storage to scale simultaneously.
The User Experience Trumps All
Finally, let’s talk about the user experience. In a perfect VDI world, you have persistent virtual desktops in which users’ settings and experience are maintained between sessions. This is the scenario that most closely mimics the real desktop experience, and people like it. With legacy infrastructure, getting the performance and capacity needed to support persistent desktops can be a real challenge.
Many gave up on VDI, thinking that they would never be able to enjoy their dreams of an efficient desktop environment. But then something interesting happened. Hyperconverged infrastructure hit the market.
Hyperconvergence and VDI Scaling and Performance
As mentioned earlier, VDI became one of the original primary use cases for the introduction of hyperconverged infrastructure into a company. It’s not hard to see where hyperconvergence solved just about all of the challenges — real and perceived — around VDI.
First, let’s talk about the ability for hyperconverged infrastructure to scale. You learned earlier that hyperconvergence natively enables linear resource scalability, which is also necessary for VDI environments to be able to keep pace with growth. As you add virtual desktops, you need to assign both CPU cores and RAM to those systems along with sufficient storage for the operating system, applications, and user files.
Performance is one of the big challenges in VDI, particularly as it relates to storage. With most hyperconverged infrastructure systems, you’re getting a combination of flash storage and spinning disk. The flash layer is used to make everything faster while the spinning disk allows you to store user files on media designed for capacity. You get the best of both worlds with hyperconverged storage systems based on hybrid storage.
Further, with hyperconverged systems that have deduplication and compression features at the storage layer, you get even more benefits. Virtual desktops are all very similar, so they are very easily reduced at the storage layer. With reduction, you’re able to store more virtual machines on the storage that exists in your hyperconverged infrastructure, which saves you a lot on disk costs. Deduplication and compression is the key technology that enables the use of persistent desktops in a VDI environment. Deduplication also massively reduced the I/O footprint for VDI systems. Being able to efficiently cache deduplicated desktop systems can virtually eliminate the various storms – boot storms and login storms – that can negatively impact performance otherwise.
Cache Is More Efficient When Deduplicated
By Brian Knudtson
In hyperconverged systems with full inline deduplication across all workloads, the data management layer tracks all of the individual references to the unique blocks that have been written to the hard disk drives (HDDs) in metadata.
This deduplication extends to data that is stored in cache. When placed into cache, a block is read from the hard disk drive (HDD), incurring a Read IO, and a copy is placed on the SSD drives. Although the block could be retrieved for a single request from a single virtual machine (VM), it could be requested again by the same VM (e.g., a block used by multiple files) or even requested by a different VM on the same host (e.g., a core Windows file). When the second request comes looking for the same block, it has already been placed in cache. Now you have two VMs benefiting from a single cached block. Extend this example to 10 VMs, and we have a single block in cache that could be worth 10 or more blocks in a non-deduplicated environment.
Continuing this example, the nine additional blocks that were accessed directly from cache generated no I/O to the back-end disks. That’s nine less HDD IOPS consumed that are now available for another read or write operation that hasn’t been cached already.
Imagine the benefits that a VDI environment could realize during a boot storm. All the VMs are based on the same template, and therefore they all have the same set of files during initial boot. Normally, 100 VMs all booting at the same time would require a significant number of HDDs, but with this hyperconverged infrastructure platform, the first VM to boot reads the block off the HDD, which promotes that block into cache. Now the next 99 VMs can all access that same block from cache. That’s a 100:1 IOPS reduction on the IOPS-bound disks.
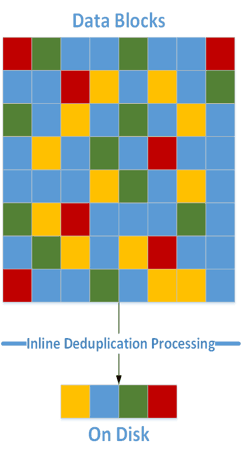
Figure 2: Deduplication in cache
Some hyperconverged systems have caching solutions that utilize RAM as a tier. In such cases, you can now apply all the same benefits just discussed and use a speed of memory-based cache. Blocks used by 100 VMs brought into memory cache at the cost of only a single VM can bring a significant performance increase to a VDI environment.
Another huge advantage for cache that comes from tracking all data as metadata is more intelligent cache-warming algorithms. Instead of simply grabbing the next block on the disk and betting on previous writes being sequential (see the IO Blender effect), the hyperconverged infrastructure nodes will calculate predictive caching based on the metadata. This leads to a much more intelligent and successful predictive cache approach.
This is just one of many advantages hyperconverged infrastructure can provide. This data efficiency, when applied to cache, not only improves the space utilization of cache, logically providing a larger cache, but also prevents read operations from going to the HDDs. It helps you improve your application performance and realize, on average, 40:1 data efficiency.
Let’s not forget about data protection and availability. In a traditional desktop environment, fully protecting workstations can be a tough task and, in the event that a workstation happens to fail, a user could be without a computer for an extended period of time. In a VDI environment, if a user’s endpoint fails, it can be very quickly replaced with another endpoint —the user simply reestablishes a connection to the persistent desktop.
But data protection in VDI goes way beyond just making it easy to get users back up and running. In fact, it comes down to being able to fully recover the desktop computing environment just like any other mission-critical enterprise application. In a hyperconverged infrastructure environment with comprehensive data protection capabilities, even VDI-based desktop systems enjoy backup and replication for user’s persistent desktops. In other words, even if you suffer a complete loss of your primary data center, your users can pick right up where they left off thanks to the fact that their desktops were replicated to a secondary site. Everything will be there — their customizations, email, and all of their documents.
Summary
With easy scalability, excellent performance capabilities, and great data protection features, hyperconverged infrastructure has become a natural choice for virtual desktop infrastructure environments.