Transparent Resource Management with Hyperconvergence
Let’s dig into more nuts-and-bolts of hardware, storage, and resiliency.
Centralizing physical infrastructure as pooled and shared resources is the core functionality of any HCI environment. Being able to manage all aspects of the pooled resources means managing both the hardware that contribute resources to the pool, and assets like virtual disks, VMs and containers that consume those resources.
Let’s look at the core areas of managing a virtual and container infrastructure.
Hardware Is Foundational
The cornerstone of every infrastructure is its hardware. In a hyperconverged world, the hardware layer is simplified into a single appliance. Making sure that this physical layer is available, performant, and scalable is a priority.
Deploying new physical appliance is a breeze due to the simplified hardware model inherent in HCI. It’s a matter of racking and stacking the system, then adding it to the appropriate cluster. These workflows are simple and accessible within the management plane of the hyperconverged system, removing the complexity of cluster management. Much of the work to keep the cluster healthy and balanced is done by automated workflows within the system, making the data center self-healing without administrative interaction.
Infrastructure lifecycle management is another advantage of HCI. These operations include keeping software versions up to date for the physical layer (UEFI and devices firmware), hypervisor, storage controller, and others.
HCI’s high level of integration makes the management plane a one-stop-shop for all software version upkeep, removing the need for a specialized update tool for each layer and component in the infrastructure.
By pulling all updates into a single system, a high level of workflow automation is achieved, making software upgrades as easy as a single click. This happens without the usual hassle of checking interoperability of new versions or the uncertain impact on the availability and performance of workloads of putting an infrastructure component into maintenance mode.
Storage Made Simple
While there are a number of different hyperconverged architectures, general design principles include separate physical servers, each containing storage devices. The storage can range widely, from hybrid flash and magnetic disk to all-NVMe systems.
The physical storage from the appliances is merged into one or more pools or namespaces. From there, storage resources are assigned to VMs, file services or containers for consumption. See Figure 1.
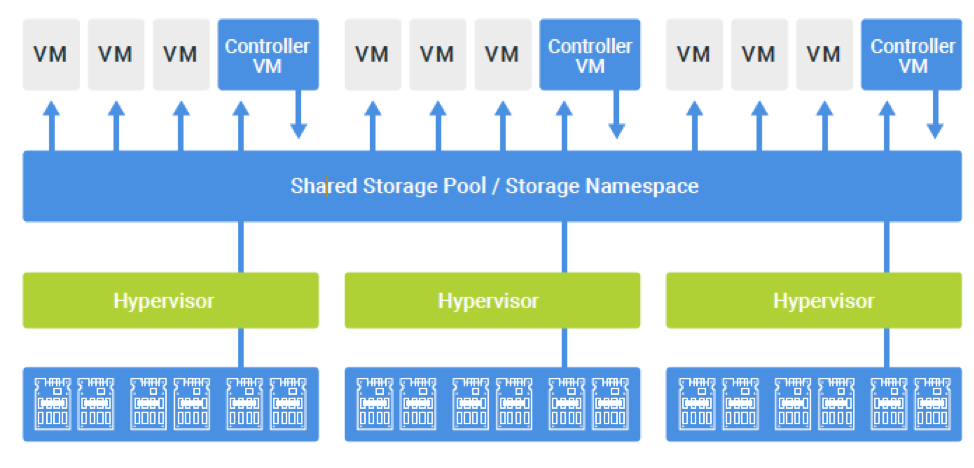
The hyperconverged platform abstracts the physical components and performs the storage-related maintenance tasks invisibly. Physical storage across all systems in a cluster are available for consumption as a single resource, often called a storage pool.
From these pools, admins can create buckets (for example, containers or volumes) as a consumable resource. Admins have a number of controls to optimize the storage usage for each use case, VM or container. Luckily, most of the so-called “nerd knobs” are simplified into easy-to-use toggles for each storage volume. Each workload has a number of capacity and performance optimization options to configure, such as compression, deduplication and erasure coding.
Compression is done both inline and post-process. Inline compression has large benefits for large or sequential I/O performance by reducing the amount of data to replicate or read from disk.
Inline compression skips random I/O. Those are picked up later by the post-process compression engine, which has the benefit of making those random I/Os relatively sequential by using spare processing capacity on the cluster.
Even though deduplication is a data reduction technique, when applied (inline) to the performance storage tier (read cache), it has a significant positive performance impact by minimizing duplication of data in the finite cache space (Figure 2).
In other words: more unique blocks are held in the cache, increasing the overall cache hit ratio. Post-process (capacity tier) deduplication is usually applied only in specific use cases to reduce on-disk overhead. These use cases include golden or master images for virtual desktop infrastructure, operating system virtual disks, and other datasets that have high duplication across VMs and containers.

Resiliency for the Enterprise Cloud
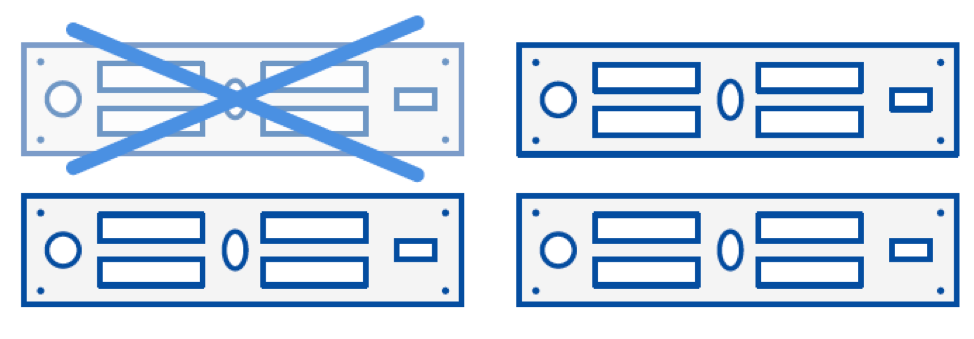
In HCI, data is protected against any single (or double) node failure by replicating data across multiple systems. The simplest way of accomplishing this redundancy is writing each block of data to two or three systems. This is very similar to how RAID-1 works in traditional systems. As this requires two or three times the capacity, it’s heavy on the storage resources, but it’s the simplest method for achieving data resiliency. See Figure 3.
Erasure Coding is a way of reducing this overhead. Instead of writing full copies to multiple systems, it provides a balance between resiliency and overhead. Erasure coding is somewhat similar to RAID-5 in that it calculates parity for each block and stripes it across different systems. When restoring from a failure, there is some impact on performance, as the parity calculations are performed to restore full resiliency; but it has little impact on normal read or write performance.
When managing a distributed storage system, having a solid overview of the current resiliency status is an important factor in day-to-day operations. It lets the administrator know the current level of protection against physical system failures, and the available wiggle room to, for instance, put nodes in maintenance for software upgrades. Accidentally removing too many systems from the working system can have disastrous effects on data consistency, performance and availability.
Many hyperconverged systems offer an at-a-glance overview dashboard of the cluster’s current resiliency status, informing admins about the number of failures the system can absorb.
In addition to data protection within a running cluster, creating resiliency against cluster and data center failure with backup and disaster recovery functionality is often included in HCI. We’ll tackle data protection shortly.
Security by Integration
HCI brings physical and virtual networking into the realm of the system administrator. There are two distinct pieces of networking to monitor, manage, and operate: the physical underlay network and the virtual overlay network
The first is the physical network, which provides connectivity between the hyperconverged appliances. This network, in its most simple form, consists of switches and cabling for interconnectivity between appliances within and across data center racks. Routers exist at the edge of the physical domain to provide connectivity outside the data center.
The physical network transports different traffic types, including the storage traffic across appliances for resiliency and availability, as well as management traffic. Workload traffic, for its part, uses the same physical transport layer, but is often separated into its own virtualized networking space.
In this virtual realm, containers and VMs are segregated into administrator-defined networking segments. Depending on the size and complexity of the infrastructure and workloads running on top, networking is done using traditional VLANs or overlay networking technologies that encapsulate traffic to decouple it from the physical layer. See Figure 4.
The underlay (A) is the transit network that carries traffic for various overlay networksOne of the pertinent use cases for using overlay technologies is microsegmentation, or the ability to outfit each VM with its own, centrally-managed firewall. This is a more granular approach to workload security and is fully integrated into the stack, moving functionality from a traditional hardware appliance into the software stack.
Integrating networking into the stack increases the visibility of workload networking, as well. Instead of manually having to correlate technical networking configuration on physical network devices with workloads, application profiles and automation code, HCI stacks have all the relevant contextual information at the ready. This allows for application and workload-centric security, removing much of the complexity and nerd knobs from networking and security.
Having physical and virtual networking side-by-side not only simplifies configuration and automation, it visualizes application communication across workloads. Understanding the flow between different workloads that make up an application makes it easy to create secure, app-centric policies.